Back in May of 2014, I used the term “lineage trap” to refer
to the distortion of historical research and its representation resulting from
an undue focus on biological lineage. A good case in point is the GEDCOM data
format which has steered the evolution of genealogy for far too long.

The reason for using this term is that the field of
genealogy is more about history than mere lineage. It would be wrong to say
that it’s specifically about family history since there are some side-lined
activities, such as One-Name Studies and One-Place Studies, which are not fully
embraced by genealogy, or by the software products that it uses. I have employed
the term micro-history — effectively a fine-grained local history — as it more
accurately encompasses these activities, as well as being inclusive of
histories relating to places, houses, military groups, organisations, clubs,
etc. I know of genealogists who have ventured into one-or-more of these
activities. Although the research, analysis, and write-up are basically the
same as for family history, our existing software products fall woefully short
of accommodating them.
This opinion has confused some people, and scared the
bejesus out of others. Why do genealogists need support for such a wide scope?
Why should they aim for such a nebulous target and risk over-complicating both our
products and our data standards?
Well, these are valid questions and deserved of a considered
answer.
My contention is that most genealogists want family history
rather than mere representations of lineage, and that micro-history can be
accommodated with only a slight generalisation from family history.
Furthermore, that generalisation gives a cleaner picture of history generally,
and provides the flexibility necessary for any unexpected or fringe avenues of
research.
Let’s start by just looking at the case of history relating
to people. Family historians cannot guarantee that their person references will
all be representable on a single family tree. Obviously there may be adoptions,
fostering, step-families, and half-siblings, but there may also be mentions of
unrelated people who played some profound part in their history. Should they be
relegated to a simple note, rather than being represented by a full Person
entity, simply because they’re unrelated? Most people would argue ‘no’, and
that implicitly means that any lineage details must therefore be disjoint, i.e.
the collection of people in the data may belong to multiple, independent trees.
By turning this statement on its head, though, then we see
it in a fundamentally different way: the lineage is a property or attribute
applied selectively within some set of people. In other words, it is the set of
people, and their relationships to historical events, which is important,
irrespective of whether there’s any shared lineage. You may be thinking that
this is a trivially different viewpoint but the repercussions will hopefully
make you think again.
Let’s just examine how we might represent unrelated people
and the shared events in their lives.

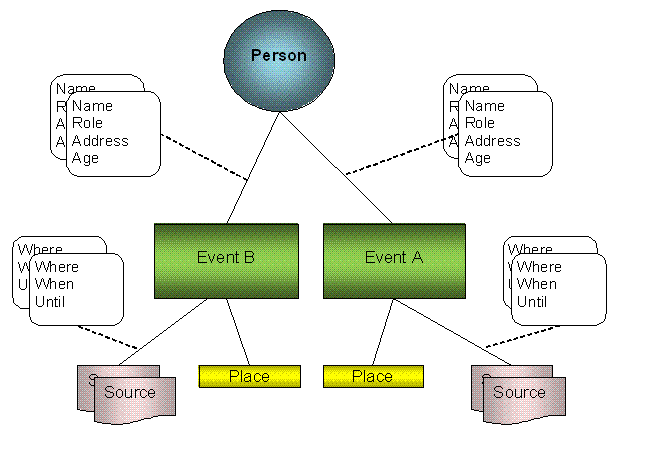
This is basically the STEMMA® approach. Each Person entity
can be connected to multiple, shared Event entities. The sources are usually
associated with the Event, as befits their STEMMA definition as “a
representation of a date, or range of dates, for which source information
exists”.
The Person and Event entities are both what might be termed
“conclusion entities” because they’re made up of the most accurate and
verifiable properties determined through research.
The associated information for the Person properties is
attached to the Event-to-Person linkage, which in turn will be specific to one
of the sources supporting that Event. Hence, there may be multiple sets of Properties:
one from each of the supporting sources. These are similar to, but not exactly
the same, as the concept known as ‘personaa’ (see Genealogical
Persona Non Grata).
The information for the Event properties (e.g. start date,
end date, place) is attached to the Event-to-source linkage, and again there
may be multiple sets if there are multiple sources for the Event. Such a set of
event properties is sometimes informally called an “eventa” in acknowledgement
of the persona concept.
This is all very symmetrical and nicely takes care of
timelines, and the separation of information and conclusion. However, STEMMA
has several distinct subject entities[1]:
Person, Group, and Place. It treats these uniformly so the above diagrams could
equally be changed to put Place or Group entities in place of the Person ones.
The only difference would be an alternative set of Property names applicable to
each of the entity types. This symmetry allows software to implement the subject
entity relationships to both Events and sources in the same way, and similarly
with tricky issues such as multiple names and name matching (see The
Game of the Name). This is ideal fodder for designs based on “classes” and Object
Orientated Programming (OOP).
So, here’s one important aspect of micro-history support. If
you were studying the history of an organisation — say the masons and their
many lodges — then any software that handled Persons in a generic, non-lineage
fashion could easily be extended to do the same for those entities. Indeed, it
has even been suggested to me that groups could be modelled using a
pseudo-person concept, but why cheat like that? Why not do it properly?
In reality, whether you’re researching family history, or
the history of the people in a given place (One-Place Studies), or the history
of people with a common surname (One-Name Studies), or military history, etc.,
then we will need a mixture of these subject entities; any single source may
contain references to persons, and groups, and places. For instance, a report
of a soldier travelling with his regiment, by ship, from one posting to
another.
But what about lineage? Well, lineage is just one form of
hierarchical arrangement that happens to be applicable to Person entities. A
hierarchy of biological lineage[2] is
characterised by each Person having a fixed relationship to just one father and
one mother. Places also have a hierarchical arrangement, such as a house, on a
street, in a city, in a state, in a country. Place hierarchies are
characterised by being time-dependent, and a Place may be split or merged (see Related
Entities). Groups have similar hierarchical considerations to those of
Places (see Revisiting
the Family Group). These different types of hierarchical linkage can be
applied to their respective entities without, in any way, changing the diagrams
above; they are independent, and optional, types of linkage that do not impact
the entity relationships to Events or to sources. Even STEMMA Events have
hierarchical arrangements (see Eventful
Genealogy).
In OOP terms, the specific classes representing these
subject entities implement their own hierarchy semantics, but they share
Event/source relationships and name handling from a generic subject-entity base
class. It should be noted that these structural differences are not one-to-one
with an on-screen representation. For instance, a family tree is just one
representation of lineage; a pedigree chart being another. Similarly, there may
be multiple ways of depicting a Place or Group hierarchy. The important point,
here, being that any product that starts with a family tree as its core concept
is artificially limiting its scope and distorting the historical picture.
Whether you want to view a specific hierarchy type, or a timeline for any or
all entity types, or a geographical representation of the entities, or some
mixture of these, is a product visualisation feature rather than a core structural
concept.
Another component of STEMMA that is essential for any type
of historical representation is narrative. If you want to document the fruits
of some research then you want narrative, not a family tree. If you want to
explain how you arrived at your conclusions then you want narrative, not some
stepwise recipe expressed in “computer speak”. If you want to share your family
history with relatives then you want real narrative, not some bunch of fields
in a database table or some computer-generated “narrative”.
This is one of the features that I’ve found hardest to
explain to people, and yet it’s probably one of the simplest. The problem is
that that non-software people are familiar with word-processors and so as soon
as you mention narrative then they think of separate documents, such as Word or
PDF. Separate documents, like these, would not be integrated with your data,
and references to people, places, groups, events, and dates, would not be
connected-up to the relevant parts elsewhere in your data. This simply means that
you need a new document format that provides the necessary semantic mark-up to
achieve this, as well as more usual mark-up for presentation. STEMMA goes
further by including mark-up to represent transcription anomalies too. So do
the software people get it? Yes, they do, but since most products will want to
squeeze your data into some relational database then there’s no easy way to
include such marked-up text in an indexed fashion; the result being that you’re
limited to little snippets of plain text instead.
Isn’t this the same as a wiki-type approach to stories?
Absolutely not! Those approaches are both a product and a data model, although
I haven’t seen one where these can be factored apart. Even if it supported
multiple marked-up documents, and events, and the historical subject entities
(person/place/group), and their respective hierarchies, and sources, then it
would still need a separately documented data model that other applications
could read. But hang on, that’s what I’ve already done!
No comments:
Post a Comment