In the episode of Mondays
with Myrt from 15 Sep 2014 (timestamp 41:30), the subject of incidental people came up. These are the
people who are mentioned in some historical source but who are not known to be related
to you. The question was posed: if your software accommodates unrelated people,
do you fully record the details of those incidental people, and do you create
an associated Person entity?
These are actually separate questions because you could
simply record the names, and other details, of those people, or you could enter
them as full Person entities, just like the other individuals in your family
tree.

There are several aspects to this topic that are worth
exploring, though, as they show it to be part of a bigger issue. For instance,
if you record such details then you want them to be searchable. Back in Ancestral
Context, I recounted how the witnesses at the wedding of Henry Woods and
Sarah Roomes were Charles Woods (Henry’s older brother) and a Sarah Oxlade. It
wasn’t until sometime after I’d identified that wedding that I realised Sarah
Oxlade not only married Charles but that they were married at the same time and
place as Henry and Sarah Roomes; thus making it a double wedding. If you were
forced to record incidental people in a simple plain-text note then that would
not be searchable in most products, and you might fail to make a similar
connection.
Of course, not every unrelated person is incidental; some
may be very significant from a family-history point of view. Also, not every person
can be classified as related or unrelated since we may not have identified them
yet from the reference in the associated source. This is important because that
person reference — sometimes described as an “evidence person”[1],
or a persona
— cannot be represented as a full-blown Person entity in your data until you
have an idea who it describes.
Let’s take a moment to look at these different cases and
what support they might require:
|
Related person
|
Requires normal Person entity (e.g. in a tree).
|
|
|
Unrelated person
|
Significant
|
Could be represented as a Person if the model supports
“disjoint trees”.
|
|
Incidental
|
Need to record source details in a searchable way.
|
|
|
Uncertain person
|
Need to record source details to support future inferences
and conclusions.
|
|
In effect, there are really just two requirements here:
either the person is represented as a full Person entity, or we simply record
their source details. Those details may later support an association with a
Person entity if, say, an incidental person turned out to be significant (as
above) or an uncertain person is eventually identified as related.
STEMMA has always supported disjoint trees and so has no
problem with representing significant unrelated people. It also provides a
means to describe a person reference, from a specific source, using an extensible
set of Property values such as name, occupation, and place of residence.
However, there was a problem.
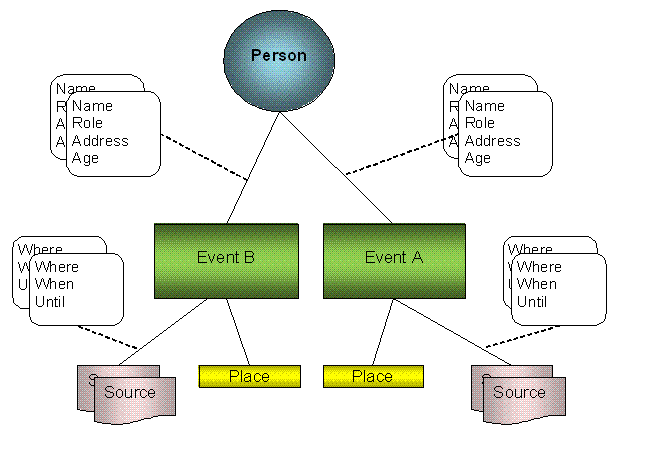
This diagram first appeared in The
Lineage Trap and shows the sets of person Properties being associated with
the link between the respective Person and the shared Event that was supported
by the source. Whether they were physically stored in the Person entity, or in the
Event entity, or in something separate that connected them, shouldn’t make a
difference given that software can elect to display a different view of the
same data; or so I believed. I was actually storing them the Person but I had
failed to consider that this being a “conclusion person” (i.e. constructed from
the aggregate evidence) meant that I was jumping
the gun. It was forcing me to make an association between the person
reference in the source and a specific Person entity. If I wasn’t sure of that
association then it was hindering me.
It also meant that I was usually forced to create a full
Person entity for incidental people; the exception being the case of narrative
text. When dealing with a transcription, for example, STEMMA’s mark-up allows
me to represent incidental or uncertain people quite easily:
<Text>
The witnesses at the wedding were <PersonRef
Key=’pCharlesWoods’>Charles Woods</PersonRef> and
<PersonRef>Sarah Oxlade</PersonRef>.
</Text>
This small bit of code marks both names as person references,
but it additionally links the first to a Person entity called ‘pCharlesWoods’.
No association is provided for Sarah. These separate cases are referred to as deep
semantics and shallow
semantics, respectively, in the STEMMA documentation. There are also
equivalents for the other types of subject reference, such as those for places
and for groups (e.g. regiments, organisations, or clubs).
This latter point is also important because I had the same
issue with Property values in my Place and Group entities as in my Person
entities. If you imagine Person being replaced by Place, or Group, in the above
diagram then the set of Property names would be different but the problem was
the same.
As of STEMMA
V3.0, Property values were moved to the other end of that connection, into
the Event entity, and into a new element, of which there was one for each
supporting source. That element contains
a sub-element for each individual subject reference in the respective source.
These elements not only contain the Property values, as described above, but
can also have relationship connections between them.

This diagram is a little busy to let me try and break it
apart. It depicts, in greater detail, the new structure for the shared Event-A
shown in the previous diagram. Its two supporting sources are now shown
separately, and each has a corresponding References element. In this
illustration, one of those References elements describes two person references
and two place references. Let’s suppose that the supporting source identifies
both of the people by name, indicates that they are related (e.g. a married
couple), and indicates that they have the same residence address, but only one
was physically present at the place of the event. Each PersonRef and PlaceRef encapsulates
the relevant Properties extracted from the source, such as their names, but
also depicts the relationships between them (the dashed lines in the diagram).
Now all but one of those four references has been associated
with a corresponding Person or Place entity. The remaining person reference remains
in this evidential form, and it is this mechanism that I would now use for
incidental or uncertain references; whether of people, places, or groups. It
would be equally possible to describe these two persons, their spousal
relationship, the two places, and the relevance of those places to the people, but
without ever connecting them to full-blown Person or Place entities. It is,
therefore, quite a powerful way of representing digested information from each
source.
A consequence of this redesign is that the PersonRef element
is now basically a persona, although
it is not described as such because the concept has been generalised to include
the PlaceRef and GroupRef equivalents.
Note that just as the Property values are extracted and
summarised items of information from the source, and so are subject to analysis
and assessment, so too are the relationships between the subjects. Just because
a source says that a woman’s relationship to a man is that of “wife” doesn’t
actually mean they were married, and an example of this very case can be found
for William Elliott and Sarah Woods in the 1881 census of this STEMMA
example. A more comprehensive coding example that deals with relationships may
be found at Census
Roles.
** NB: This design was revised in STEMMA V4. See Source
Mining and STEMMA
4.0 **
[1] Whether these are
considered evidence, rather than
simply information, depends on
whether you consider them to substantiate the existence of an associated
individual. The use of the informal, and contentious, terms “evidence person”
and “conclusion person” has recently been debated within FHISO.
No comments:
Post a Comment