Announcing the release of SVG-FTG V6.2, and its main features. It is true that V6.1 was only released a short while ago, but I need to clear my own wish-list and a list of suggestions from users in order to proceed with other work. It is expected that V6.2 will be last feature release for a much longer period. Details on availability can be found on the summary page: SVG-FTG Summary.
An underlying theme in this version is a better ability to integrate with other products, including better support for automation, support for usage within <iframe> elements, local application registration files (for easy customisation), documentation of the private GEDCOM records specific to SVG-FTG, and a new application to get person or family information from an external source. The value of this lies in the fact that SVG-FTG has created a niche for interactive graphical web-based presentation trees that rely on standard technologies and that do not require a database or paid subscription.
The feature highlights below will mention the relevant sections in the updated documentation.
Private and Living Persons
It is now possible to hide the details of living and/or private persons. The latter feature allows specific persons to be flagged as private, irrespective of whether they are living or not. There are independent text and image substitutions for these two scenarios. There are also guidelines for how to maintain pruned editions of your tree where persons and families may be physically removed for selected readership.
An additional menu option has had to be provided to ensure that all person and family keys are obscured, and no longer relate to names or captions.
See "User Guide : Hiding Selected Persons".
Tabbed Content in Notes
Biographical and historical notes can now utilise tabs to better organise larger amounts of data. For instance, you may want to separate vital events from memories, or from document scans.
The beginning of a new tabbed section can be easily marked (or modified) using a new button on the 'HTML Toolbar' in the Edit-Person or Edit-Family forms. These will be rendered as selectable tabs when viewing the notes in the 'Information Panels' application, e.g.
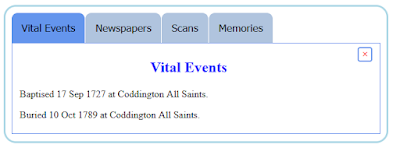
A similar rendering is provided when they are viewed within the 'Expand Notes' application:
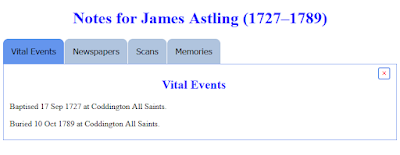
See "User Guide : HTML Editing : Tabbed Content", and "Program Notes : Tabbed Content".
Copy and Paste
The copy-and-paste features in the Tree Designer, and when bringing in elements from an imported GEDCOM file, were quite small-scale (i.e. multiple individuals, or a single family and their children). This has been extended with a 'Copy Descendants' option that copies a spouse-pair, their children, spouses of children, spouses of spouses, and so on down the generations.
See "User Guide : Tree Designer", and "User Guide : GEDCOM Browser".
Resizable Information Panels
The pop-up information panels used for displaying notes may now be resized using "grab handles" in the bottom-right corners. If you click on these then you can drag them up/down and left/right to resize a panel.
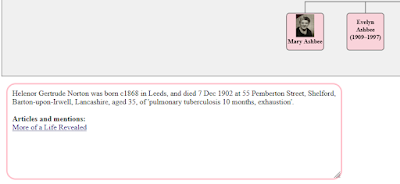
See "User Guide : Applications and Services : Information Panels'.
Customising Applications
Additional elements have been added to the application registration XML files, and these allow your custom XML files to more easily modify application configuration or CSS styling.
See "Program Notes : Application Development : Header and Trailer Code".
Local tree-specific registrations files are now supported as a supplement to the system ones (which apply to all trees), and may be specified using the new header setting AppSrvFile, or through the Advanced-Settings form.
See "Program Notes : Application Development : Application Registration".
External-Information Application
A new interactive application has been added to link to information in an external source. This 'External Information' application will follow a hyperlink when clicking on a person box or family circle, and better helps integration with data held in other products.
See "User Guide : Applications and Services : External Information".
Automation
There are new command-line options to make automation easier. These include ones for loading and converting GEDCOM files, running minimised, establishing a log file to capture all progress messages, and terminating SVG-FTG when automated tasks are completed.
See "User Guide : Command-line and Shortcuts".
Iframe usage
There are new header settings (Iframe=boolean and ValidOrigins=list, accessible through the Advanced-Settings form) for creating a tree that may be embedded in the <iframe> element of a hosting page. The support includes a simple communication service such that the hosting page can request information from the embedded tree. A common case would be asking for the size of the SVG frame so that the enclosing <iframe> element can be resized appropriately. The ValidOrigins setting a security features that allows the embedded tree to checking that the requests come from an authorised page.
See "Program Notes : Configurations : Iframe Usage".
Image Errors
Image-loading errors are now better handled, and are indicated in both the Tree Designer and the browser by substituting a custom error marker.
See "User Guide : Tree Designer : Person Images".
Alternative Fonts
The standard font used in person-boxes was 13px Times New Roman. The only variation of this occurred when Small=True (which was also implied if Blog=True), in which case the font size was reduced to 10px. There is now explicit control over the choice of font style and size using the new header settings: FontFamily and FontSize. The chosen font can also be styled using new FontBold and FontItalic settings.
See "Program Notes : Configurations : Fonts".
Access to All Settings
A new form provides access to every possible header setting in a tabular form that may be more familiar to developers. This is an additional option and does not displace the original forms that use logical grouping to organise the supported settings.
See "User Guide : Tree Designer : All Settings".
